
Build an AI Agent with n8n: Step-by-Step 2026 Guide
Most n8n agent tutorials teach you how to build. None tell you why your agent skips critical steps in production. This guide covers every step to build an AI agent with n8n: trigger, LLM, memory, and tools, plus the guardrails that keep it reliable under real traffic. You leave with a production-aware agent, not a demo.

Traditional automation follows a fixed sequence. An n8n AI agent follows a goal. That distinction matters more in 2026 than ever, because real business operations rarely fit a clean predetermined path. When a customer inquiry needs a knowledge base lookup, a drafted reply, and an escalation decision, a rigid if/then chain breaks down fast. An agent reasons through those steps on its own.
When you build an AI agent with n8n, you get a workflow that receives an objective, selects the right tools, calls them in sequence, and loops until the task is complete. No human re-entry required at each decision point. n8n makes this possible without writing code. It is an open-source, low-code platform with native LangChain integration, 70+ AI nodes, and a self-hosting option that keeps sensitive data on your own infrastructure.
This guide walks through every step, from a blank canvas to a working, production-aware AI agent, including the memory choices and reliability guardrails most tutorials skip entirely.
What You'll Learn About Building AI Agents in n8n
- What the n8n AI Agent node does and how it differs from a standard LLM node: the Agent node reasons, selects tools, and loops autonomously rather than returning a single text response.
- The 7 concrete steps to build a working agent from scratch, covering trigger setup, LLM connection, memory, tools, system prompt, and testing.
- Which LLMs to connect, including OpenAI, Anthropic Claude, and local models via Ollama with no API key required.
- How to choose production-safe memory and why Simple Memory breaks in queue mode deployments.
- The 4 agentic workflow design patterns in n8n and when to use each.
- The non-deterministic production failure pattern most tutorials ignore, and how to guard against it with deterministic techniques.
What Is an n8n AI Agent and Why Does It Matter?
An n8n AI agent is an autonomous workflow built on the AI Agent node, which connects a large language model to a set of callable tools. The agent receives a goal, reasons about which tools to use, calls them in order, and loops until the task is complete: behavior no standard automation workflow can replicate.
In a traditional n8n workflow, every execution follows the same path. Node A runs, then Node B, then Node C. Same input, same output, every time. An AI agent works differently. It evaluates the situation at runtime, picks the relevant tools, and may take a completely different path on each run depending on what the input actually says.
The n8n AI Agent node runs on a native LangChain foundation, meaning the reasoning loop, tool-calling protocol, and memory management all follow LangChain's established architecture. n8n 2.0 launched in December 2025 and deepened this integration significantly. By early 2026, the platform had expanded to over 70 AI-specific nodes with improved support for multi-agent orchestration.
AI Agent vs. Traditional n8n Workflow: Key Differences
| Feature | Traditional Workflow | AI Agent |
|---|---|---|
| Decision-making | Predefined logic paths | LLM reasons at each step |
| Data handling | Passes data in fixed node order | Selects which sources to query dynamically |
| Adaptability | Requires manual workflow editing | Adapts reasoning based on input content |
| Tool usage | All nodes execute in sequence | Agent chooses which tools to call per run |
| Failure mode | Predictable, same failure point | Non-deterministic, may skip steps silently |
💡 Expert Tip: The "Failure mode" row is the most important distinction for any production deployment. A traditional workflow fails the same way every time, which makes debugging straightforward. An AI agent can succeed on nine consecutive runs and silently skip a critical tool call on the tenth. Section 6 covers exactly how to guard against this.
How to Build an AI Agent with n8n in 7 Steps
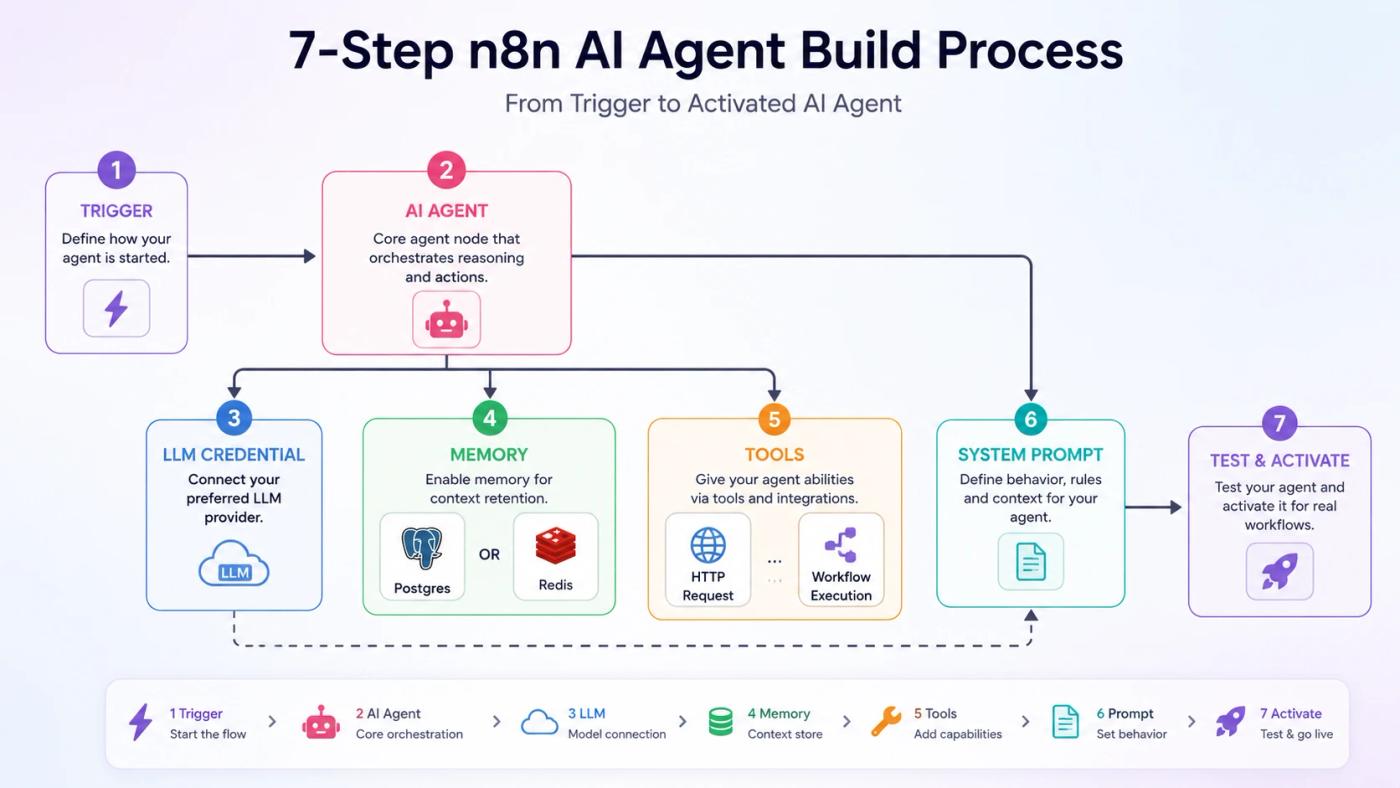
Building an n8n AI agent requires four core components working together: a trigger that starts the workflow, an AI Agent node that reasons using an LLM, memory that preserves conversation context, and tool sub-nodes the agent can call to take action. The steps below walk through each component in order.
Step 1: Create a Workflow and Add a Trigger
Open n8n and create a new workflow. Choose Chat Trigger for conversational agents, Webhook for external system triggers, or Schedule Trigger for time-based autonomous runs. Name the workflow clearly before moving on. That name matters when you call it as a sub-agent later.
Step 2: Add the AI Agent Node
Add the AI Agent node after the trigger. As of n8n v1.82.0+, the agent type selector no longer exists. All AI Agent nodes now run as Tools Agent by default, which was already the recommended setting. At least one tool sub-node must be connected; without it, the node cannot execute.
Step 3: Connect a Chat Model
Connect an LLM credential under the Chat Model input. n8n natively supports OpenAI (GPT-4o for complex reasoning), Anthropic Claude, Google Gemini, Groq, and DeepSeek. For environments where external API calls are not permitted, connect a local model via Ollama using its endpoint URL as a credential. No API key required.
📌 Pro Insight: Ollama is particularly valuable for healthcare, legal, and finance teams with strict data residency requirements. The setup takes minutes. One critical caveat: open-weight local models are significantly weaker at tool-calling than cloud-hosted models like GPT-4o. The AI Agent node connects to Ollama via a standard API interface, but actual tool-call reliability depends entirely on the model's function-calling capability. Use a function-calling-tuned model variant and validate tool-call accuracy against your specific workflow before any production deployment.
Step 4: Configure Production-Safe Memory
Connect a memory sub-node to preserve conversation context across messages. Simple Memory is development-only: it resets on restart and is incompatible with queue mode, because n8n cannot guarantee the same worker handles consecutive calls from the same user. From n8n 2.4.6+, Simple Memory is hidden from the nodes panel when queue mode is active.
For production, choose one:
- Postgres Chat Memory: durable, survives restarts, works across all workers. The right choice for most deployments. One caveat: without a context window limit or summarization strategy, long user sessions grow stored history unboundedly, eventually exceeding the model's context limit and inflating API cost on every subsequent turn. Configure a message history cap or rolling window before going live with real users.
- Redis Chat Memory: faster read/write for high-traffic, real-time agents where latency matters.
In both cases, assign a dynamic session ID per user, derived from a user ID or UUID in the trigger payload, to prevent cross-user memory contamination.
Step 5: Attach Tool Sub-nodes
Connect tool sub-nodes to give the agent callable functions. Three methods cover most use cases: HTTP Request Tool for any external API, native n8n service nodes as tools (Gmail, Slack, Google Sheets), and the Execute Workflow Tool to call a separate n8n workflow as a sub-agent with its own isolated logic.
Step 6: Write an Effective System Prompt
Set the System Message in the AI Agent node options. Define the agent's role, constraints, output format, and escalation rules. Specific, concrete prompts cut non-deterministic behavior. Vague prompts are the primary source of inconsistent tool-call decisions in production.
⚠️ Common Mistake: A prompt that says "answer user questions" gives the agent no guardrails. Try this instead: "You are a support agent for [product]. Reply only using information from the attached knowledge base. If confidence is below 80%, escalate to human review. Always respond in JSON with keys: answer, confidence, sources."
Step 7: Test, Debug, and Activate
Use the built-in Chat panel to test the agent in isolation. Review the execution log to inspect every tool-call decision step by step. Activate only after validating against varied real inputs, not just the one example that always works.
Production agent debugging goes further than single-run inspection. Open the AI Agent node's execution detail to review intermediate reasoning steps, not just the final response. Check which tools were called, in what order, and what each returned. Read the token usage from the LLM sub-node output across several test runs to establish a real cost baseline before traffic scales.
Non-deterministic failures rarely reproduce on demand. They appear as patterns across many runs, which means you need traces, not reruns. For high-volume deployments, external tracing via LangSmith provides persistent storage of agent reasoning chains and enables cross-run pattern analysis. Concurrency failures, where two sessions interfere unexpectedly under queue mode, are invisible in manual single-run testing and only surface under load. Enable queue mode in your test environment and simulate multiple concurrent sessions before activating any workflow with real users.
4 Agentic Workflow Design Patterns in n8n: When to Use Each
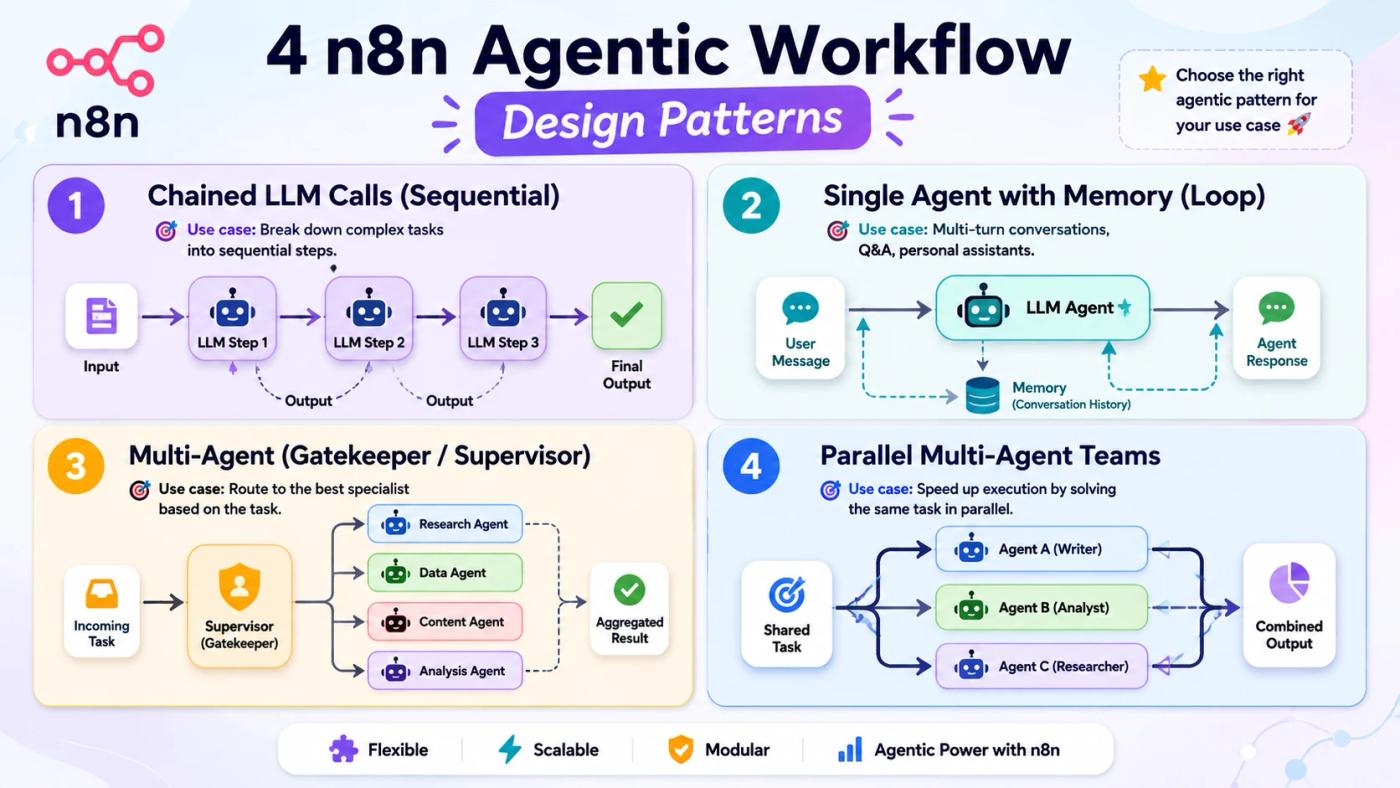
n8n supports four documented agentic workflow patterns: Chained Requests for sequential LLM calls, Single Agent for conversational workflows with memory, Multi-Agent with Gatekeeper for modular task delegation under centralized control, and Multi-Agent Teams for parallel specialized agents on complex tasks. Pattern choice depends on task complexity and how much autonomy each agent needs.
Most beginners default to Single Agent for everything. That works early on, but knowing all four patterns prevents costly rework as requirements grow.
Chained Requests: sequential LLM calls where each output feeds the next, with intermediate processing between steps. Use when the task has clear, predictable sub-steps and cost control matters.
Single Agent with State: one AI Agent node with persistent memory handling multi-turn conversations. Use for customer-facing chatbots, support bots, and any workflow where context continuity across messages is essential.
Multi-Agent with Gatekeeper: a supervisor agent routes tasks to specialized sub-agents and consolidates results. Use for complex workflows that need modular separation of concerns, like lead qualification with separate research, scoring, and outreach agents.
Multi-Agent Teams: parallel specialized agents collaborate on a shared task with distributed decision-making. Use for large-scale content pipelines, parallel data processing, or any task that benefits from simultaneous workstreams.
💡 Expert Tip: Start with Single Agent. Move to Multi-Agent with Gatekeeper only when you find yourself cramming more than 8 tools into one agent node. Tool-count degradation is a more common production issue than needing multi-agent collaboration too early.
What Most n8n Agent Tutorials Don't Tell You
Building the agent is step one. Keeping it reliable in production is where most tutorials stop short. Top-ranking guides teach construction. Almost none address what happens when an LLM-based agent hits real traffic, variable inputs, and the pressure of irreversible actions. n8n's engineering analysis and community post-mortems from 2026 deployments confirm this gap exists.
Why Your n8n Agent May Skip Critical Steps in Production
LLM reasoning is probabilistic. The same input can produce different tool-call sequences across runs. That is not a bug; it is the nature of language model inference.
The real-world consequences are documented. Community members have reported agents that correctly call all required tools on nine out of ten runs, then silently skip a critical step on the tenth with identical inputs. One n8n community case study showed an invoice classification agent routing the same document differently across consecutive runs, with no change to the input data at all. Any workflow where a skipped step triggers an irreversible action (sending an email, updating a CRM record, processing a payment) cannot rely on LLM reasoning alone to guarantee that step executes.
How to Add Deterministic Guardrails Inside Agentic Workflows
Four techniques address this reliability gap:
- Use IF/Filter nodes before and after agent decisions to validate inputs and outputs against expected formats before downstream execution fires.
- Wrap critical, irreversible logic in Execute Workflow Tool: sub-workflows execute deterministically and independently of the agent's reasoning path.
- Set a maximum iteration cap in the AI Agent node to prevent runaway loops against a paid LLM API.
- Implement a human-in-the-loop approval step using n8n's Wait node with a webhook resume for any action that cannot be undone.
⚠️ Warning: A strong system prompt reduces inconsistency but cannot eliminate non-determinism. Prompts operate in the probabilistic layer. Guardrails operate in the deterministic layer. Production-safe agents need both.
5 Practical Use Cases for AI Agents Built with n8n
The most common n8n AI agent deployments in 2026 cover email triage, customer support with knowledge retrieval, internal Q&A bots, content pipelines, and lead qualification. Each use case combines the AI Agent node with specific tool sub-nodes and a memory backend suited to the interaction pattern.
- Gmail Triage and Auto-Draft Agent: a Gmail Trigger watches an inbox; the agent classifies intent, drafts a reply grounded in a knowledge base, and routes to human review or sends automatically based on a confidence threshold. Teams processing high volumes of inbound email reclaim significant time by letting the agent handle first-draft composition.
- Customer Support Bot with RAG Memory: the agent queries a Pinecone or Supabase vector store containing product documentation, retrieves relevant chunks, and answers grounded in real data rather than general model knowledge. This cuts hallucination on product-specific questions significantly. One production reality to account for: RAG relocates the hallucination risk from the model to the retrieval layer. Poor document chunking splits related information across fragments so neither retrieves completely. A high top-k value floods the prompt with marginally relevant chunks, diluting the useful result. When retrieval misses, the agent answers from whatever it retrieved with full confidence, producing a wrong answer that looks correct. Add an explicit instruction to escalate when no sufficiently relevant chunk is found rather than relying on model confidence alone. For a deeper look at structuring your deployment around this pattern, the n8n AI Automation Guide 2026 covers cloud versus self-hosted tradeoffs in detail.
- Local LLM Agent for Private Data: for healthcare, legal, or finance teams that cannot send data to external APIs, an Ollama-hosted model via URL credential, self-hosted n8n, and Postgres Chat Memory on the same server keeps every token on-premise with zero external exposure. One operational requirement: validate the local model's tool-calling accuracy before going live. A model that silently skips tools and falls back to parametric memory defeats the compliance purpose of self-hosting entirely.
- Internal Knowledge Bot: agents ingest Q&A pairs from a web form into an n8n data table; a second Chat Trigger workflow answers employee questions grounded in that submitted content, not general model knowledge. Works well for onboarding docs, HR policy lookups, and IT troubleshooting guides that change frequently.
- Lead Qualification Agent: a Webhook receives new lead data from a CRM; the agent researches the lead via web search tool, scores against qualification criteria, drafts a personalized outreach email, and logs the result back to the CRM via HTTP Request tool. For teams evaluating where this fits in a broader strategy, see AI automation use cases for business in 2026.
The Hidden Cost of Agentic Loops
Most teams assume AI agent cost is determined by model pricing. In practice, cost is driven by iterations.
Every agent reasoning loop resends the full accumulated context to the LLM: system prompt, conversation memory, all prior tool outputs, and the current user request. A workflow that calls five tools does not generate five API calls. It generates five or more, and each one carries a larger context window than the last. By the final iteration, the model is processing significantly more tokens than it did on the first call, even if the user sent a single short message.
Memory compounds this over time. Postgres Chat Memory stores every conversation turn, and each new message includes the full session history. A returning user mid-way through a long session triggers a far more expensive call than a new user asking the same question. Without a windowing strategy, your longest sessions become your most expensive ones by a wide margin.
The cheaper model paradox catches teams off guard. A lower per-token price does not guarantee a lower cost per completed task. A model that reasons inefficiently and burns extra iterations to reach the same output costs more overall than GPT-4o finishing the task in fewer steps. The metric that matters is cost per completed task, not cost per million tokens.
Three levers directly control agentic cost: setting a maximum iteration cap on the agent node, applying a message history limit on memory so only recent turns re-enter the prompt, and matching model capability to actual task complexity so fewer iterations are needed to produce a good output.
💡 Expert Tip: Build a cost baseline before going live. Run ten to twenty representative test conversations and read the token count from the LLM node's output data. Multiply that by your model's per-token rate to get a real cost-per-conversation figure. It is almost always higher than the estimate teams calculate from a single demo run.
n8n vs Zapier for Building AI Agents: Key Differences
n8n charges per workflow execution regardless of how many nodes it contains. Zapier charges per task, meaning each individual step inside a workflow counts separately. For multi-step agentic workflows where an agent may call five or more tools per run, this billing difference becomes significant at scale, particularly for high-volume deployments.
n8n vs. Zapier: Capability Comparison
| Capability | n8n | Zapier |
|---|---|---|
| Pricing model | Per execution (unlimited steps) | Per task (each step counted) |
| Self-hosting | Yes, full self-hosted option | No |
| Open-source access | Yes | No |
| AI agent architecture depth | Native LangChain, multi-agent orchestration | Basic AI steps via Zapier Central |
| Local LLM support | Yes, via Ollama URL credential | No |
n8n is the stronger choice for technical teams building complex agentic logic, custom tool integrations, or data-sensitive workflows that need self-hosting. Zapier suits non-technical operators who need simple AI steps across its 8,000+ app catalog without infrastructure overhead. The decision comes down to control versus convenience, not capability ceiling. If your agent stack involves choosing between LLM providers, the ChatGPT Agents vs Claude Agents comparison covers the cost and performance tradeoffs that affect both platforms.
7 Common Mistakes When Building n8n AI Agents (and How to Fix Them)
- Using Simple Memory in production: it resets on restart and fails silently in queue mode. Switch to Postgres Chat Memory before real users touch the workflow.
- Hardcoding a static session ID: all users share one memory thread, leaking context across separate conversations. Derive the session ID dynamically from the user's identity in the trigger payload.
- Writing vague system prompts: generic instructions produce inconsistent tool-call decisions across runs. Include the agent's role, output format, escalation rules, and at least one example of a correct response.
- No iteration cap on the agent node: an unguarded agent can loop indefinitely against a paid LLM API. Set a maximum step count in node settings before activating any production workflow.
- Giving the agent too many tools: more than 8 to 10 tools degrades tool-selection accuracy. Group related logic into sub-workflows and expose them as a single callable unit via Execute Workflow Tool.
- Skipping error handling on tool nodes: a failed HTTP request with no fallback silently halts the agent mid-task. Enable "Continue on Fail" and connect an error workflow for graceful degradation.
- Oversized LLM for simple tasks: running GPT-4o on a classification task wastes token budget without improving accuracy. Match model size to reasoning complexity: smaller models for routing and classification, larger ones for multi-step synthesis.
💡 Expert Tip: Mistakes 1, 2, and 4 cause silent production failures with no visible error messages. They pass every development test because dev environments typically run single-worker, low-traffic conditions. Test with queue mode enabled and multiple simulated users before going live.
Frequently Asked Questions About Building AI Agents with n8n
Do I need to know how to code to build an AI agent with n8n?
No. n8n's visual node builder handles the core agent architecture without writing code. You connect nodes by dragging lines between them and configure settings through dropdown menus. An optional Code node lets developers inject custom JavaScript or Python for advanced data transformations, but a fully functional agent, including memory, tools, and LLM connection, requires no coding.
Can n8n connect to local LLMs like Ollama instead of OpenAI?
Yes. n8n supports Ollama-hosted models via a URL credential in the Chat Model settings. Point the credential at your Ollama endpoint (for example, http://localhost:11434) and select your model. No API key required. This keeps all data on-premise and suits regulated industries or teams with strict data residency requirements. One caveat applies: validate the local model's tool-calling accuracy before production use, as open-weight models vary significantly in function-calling reliability.
What is the best AI agent design pattern in n8n for beginners?
Start with the Single Agent pattern: one AI Agent node, Postgres Chat Memory for any real-user-facing workflow, and two to three tool nodes. It is the simplest pattern to debug and the easiest to grow into a Multi-Agent with Gatekeeper setup as requirements expand.
Does n8n support multi-agent systems?
Yes. n8n supports two multi-agent patterns: Multi-Agent with Gatekeeper, where a supervisor routes tasks to specialized agents, and Multi-Agent Teams, where parallel agents collaborate on a shared goal. Both use the Execute Workflow Tool to call sub-agent workflows from a parent workflow, keeping each agent's logic modular and independently testable.
How does n8n handle AI agent memory across sessions?
Memory persistence depends on the memory node chosen. Simple Memory is session-only and incompatible with queue mode. Postgres Chat Memory stores conversation history in a database, durable across restarts and shared across workers. Redis Chat Memory offers faster read/write for high-traffic agents. Every memory node requires a unique session ID per user to maintain conversation isolation.
Start Building Your First n8n AI Agent Today
An n8n AI agent is not a smarter automation workflow. It is a fundamentally different architecture. Where a standard workflow follows a fixed path, an agent receives a goal and reasons its way to completion using four components: a trigger, an LLM, persistent memory, and callable tools.
The two production realities most tutorials miss are memory backend choice (Simple Memory fails in queue mode) and deterministic guardrails for actions the agent cannot undo on its own.
Start with the Single Agent pattern: a Chat Trigger, Postgres Chat Memory, and two to three tool nodes. Test against real inputs before activating, then expand complexity as confidence grows. For teams building on proven foundations, the top no-code AI tools for productivity in 2026 covers the broader automation stack that pairs well with n8n agents in production.
n8n's agentic capabilities continue expanding through 2026, with enterprise observability features and deeper multi-agent orchestration already in the roadmap. The architecture you build today is the one you scale tomorrow.
Related Articles




