
Claude vs ChatGPT 2026: Best AI for Content, Code & Research
Most Claude vs ChatGPT 2026 comparisons miss the part that matters: cost per finished task, not cost per token. This guide tests Opus 4.7 against GPT-5.5 across coding, writing, and research with verified benchmarks and real pricing math. You'll know which AI fits your workflow before paying for either.

Anthropic shipped Claude Opus 4.7 on April 16, 2026. OpenAI followed on April 23 with GPT-5.5, just seven days later. Both arrived with 1M-token context windows, both targeted serious work, and both cost $20 a month at the consumer tier.
So the obvious question, which one should you actually use, has stopped being a useful question. The right way to frame Claude vs ChatGPT in 2026 is not which model wins overall. It is which model wins your specific workflow.
Each platform now has clear strengths and clear blind spots, and choosing wrong wastes both money and hours. This guide compares both across the three lanes that matter most: content writing, coding, and research. You will see who wins each, why, and the cost trap most reviews miss.
Quick Verdict: Claude vs ChatGPT — Who Wins What
In 2026, neither Claude nor ChatGPT dominates across the board. Claude Opus 4.7 wins on long-form writing, codebase work, and document analysis. GPT-5.5 wins on agentic coding, deep web research, and multimodal output. The right pick depends on the specific job, not on raw model rankings.
- Content writing → Claude Opus 4.7 (cleaner long-form prose, fewer AI cliches)
- Agentic coding → GPT-5.5 (stronger plan-and-execute through Codex)
- Codebase resolution and PR work → Claude Opus 4.7 (leads on real software engineering in large repos)
- Deep web research → ChatGPT (more mature browsing and multi-source synthesis)
- Long-document analysis → Claude (better precision recall on uploaded files)
- Image, voice, and multimodal output → ChatGPT (native image generation Claude does not offer)
Claude and ChatGPT in 2026: The Current State
In May 2026, both platforms have entered a new generation. Anthropic's flagship is Claude Opus 4.7, with a focus on coding, reasoning, and document work. OpenAI's flagship is GPT-5.5, built around agentic computer use and multimodal output. Both share the same 1M-token context window and the same $20 starting subscription tier.
What Claude Looks Like in 2026
Claude Opus 4.7, released April 16, anchors the lineup. It carries a 1M-token context window, an adaptive thinking mode, and a new tokenizer that uses up to 35% more tokens on the same input. Claude Code handles autonomous software engineering inside repositories, while Claude Research runs deep analysis across uploaded documents.
What ChatGPT Looks Like in 2026
GPT-5.5 and GPT-5.5 Pro, released April 23, 2026, sit at the top of the ChatGPT stack. Both share the same 1M-token window. ChatGPT Canvas drives side-by-side writing, Deep Research handles multi-source web synthesis, and Codex powers autonomous coding flows. Native image, voice, and video output round out the omnimodal experience.
On the consumer side, both subscriptions still anchor at $20 a month. Claude Pro and ChatGPT Plus remain the default entry points for serious users.
Side-by-Side: Benchmarks, Features & Pricing
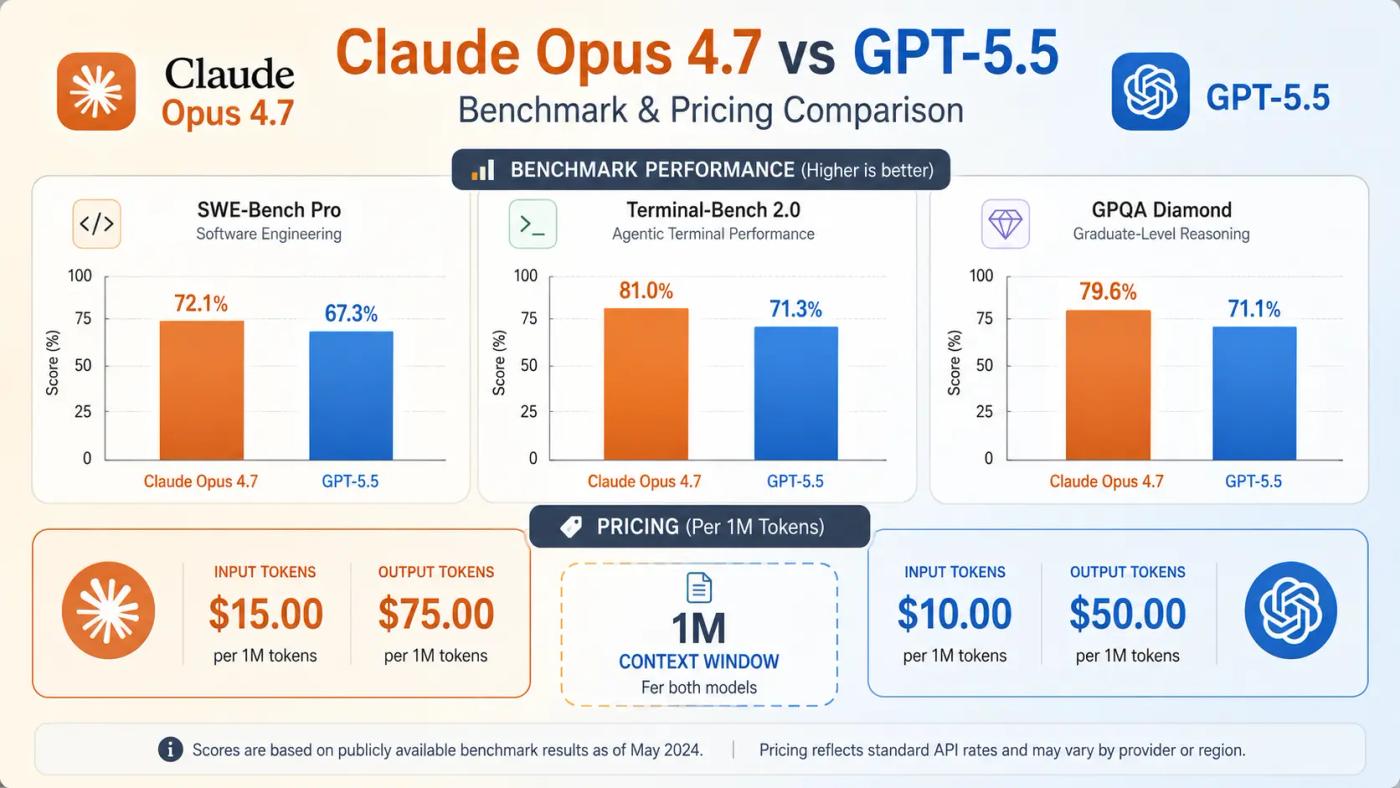
On 2026 benchmarks, Claude Opus 4.7 and GPT-5.5 trade wins by category. Claude leads on agentic coding, multi-tool use, and visual reasoning. GPT-5.5 leads on terminal workflows, math, and long-running knowledge work. Pricing sits close on input tokens and within $5 on output tokens, and both ship 1M-token context windows.
Coding Benchmarks: SWE-Bench Pro, Terminal-Bench 2.0, CursorBench
On SWE-Bench Pro, which tests real software engineering issues across multiple languages, Opus 4.7 leads with 64.3% versus GPT-5.5's 58.6%. The picture flips on Terminal-Bench 2.0, where GPT-5.5 dominates command-line workflows at 82.7% versus Opus 4.7's 69.4%. On CursorBench, which measures real IDE coding tasks, Opus 4.7 jumped to 70% at launch.
Reasoning, Knowledge & Computer-Use Benchmarks
Across reasoning and knowledge-work tests, the wins split. Opus 4.7 leads GPQA Diamond (94.2% vs 93.6%) and MCP-Atlas tool orchestration (77.3% vs 75.3%). GPT-5.5 leads GDPval at 84.9% vs 80.3%, OpenAI's knowledge work benchmark covering 44 occupations, and edges out Claude on OSWorld-Verified (78.7% vs 78.0%). On FrontierMath Tier 4, GPT-5.5 holds the largest single-benchmark gap at 35.4% vs 22.9%.
Pricing & Context Window Comparison
Sticker prices land close. Claude Opus 4.7 runs $5 per million input tokens and $25 per million output tokens. GPT-5.5 is $5 input and $30 output. Both carry a 1M-token context window with up to 128K output tokens. Consumer plans match at $20/month for both Claude Pro and ChatGPT Plus.
| Dimension | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|
| Release date | April 16, 2026 | April 23, 2026 |
| Context window | 1M tokens | 1M tokens |
| Max output tokens | 128K | 128K |
| Input price (API) | $5 / 1M tokens | $5 / 1M tokens |
| Output price (API) | $25 / 1M tokens | $30 / 1M tokens |
| SWE-Bench Pro | 64.3% | 58.6% |
| Terminal-Bench 2.0 | 69.4% | 82.7% |
| GPQA Diamond | 94.2% | 93.6% |
| OSWorld-Verified | 78.0% | 78.7% |
| GDPval | 80.3% | 84.9% |
| Consumer plan | Claude Pro ($20/mo) | ChatGPT Plus ($20/mo) |
Where Each Wins: Content, Coding & Research
In 2026, the comparison breaks cleanly into three lanes. Claude Opus 4.7 leads on long-form content and codebase work. GPT-5.5 leads on agentic coding and broad web research. The gaps are large enough in each lane that pairing the right tool to the right job changes both quality and cost meaningfully.
Claude vs ChatGPT for Content Writing
For content writing, Claude is the stronger default in 2026. Claude Opus 4.7 produces more natural long-form prose with fewer AI-style tells, holds tone consistency over thousands of words, and handles complex briefs without drifting. ChatGPT wins where writing pairs with images, Canvas edits, or live data through Deep Research. Pure text quality favors Claude; multi-format publishing favors ChatGPT.
In practice, writers drafting blog posts, books, or long essays usually default to Claude for tone control across the full piece. Marketers producing social posts with native visuals lean toward ChatGPT, since image generation lives inside the same chat. Newsletters with embedded charts? ChatGPT. A 5,000-word feature with one consistent voice? Claude.
Claude vs ChatGPT for Coding & Developers
For coding, the answer depends on the work. Claude Opus 4.7 wins codebase resolution and PR work, scoring 64.3% on SWE-Bench Pro to GPT-5.5's 58.6%. GPT-5.5 wins agentic coding pipelines through Codex, leading Terminal-Bench 2.0 at 82.7% versus 69.4%. A 15,000-developer survey in February 2026 found 71% of regular AI-agent users on Claude Code (Pragmatic Engineer).
Here's the practical split: large repos and multi-file refactors favor Claude. Long-running terminal automation and autonomous PR-to-merge agents favor GPT-5.5.
Claude vs ChatGPT for Deep Research
For deep research, the right tool depends on where your sources live. ChatGPT Deep Research has the more mature web-browsing pipeline, beating Claude on BrowseComp (84.4% vs 79.3%) by pulling and synthesizing across many live web pages. Claude Research wins document-grounded analysis: uploaded PDFs, internal corpora, and books, where precision recall on long context matters more than browsing breadth.
So the rule is simple. Researching a fast-moving topic on the open web? ChatGPT. Synthesizing a stack of uploaded reports, contracts, or papers? Claude.
The Hidden Cost Most Comparisons Miss — Token Efficiency in 2026
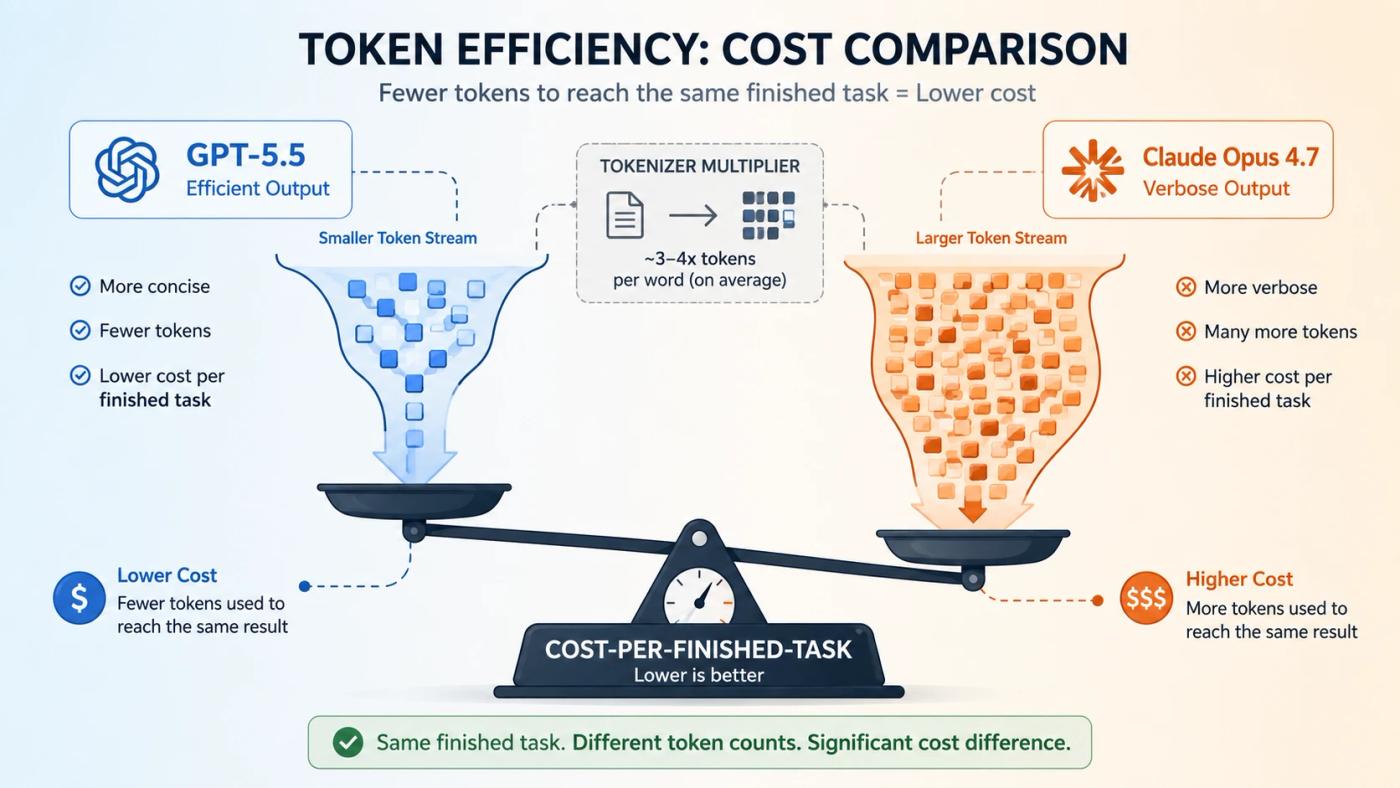
Most Claude vs ChatGPT comparisons stop at sticker price. The real economics in 2026 sit in cost per finished task, not cost per token. GPT-5.5 finishes coding tasks with far fewer output tokens, while Opus 4.7's new tokenizer counts more tokens for the same input. The bill that matters lands somewhere between the rate cards.
Why Per-Token Pricing Lies
Sticker comparisons assume both models burn the same tokens on the same task. They don't. GPT-5.5 produces about 72% fewer output tokens than Opus 4.7 on identical coding tasks. The model at $30 per million output can finish cheaper than the model at $25 if it writes a third as much.
The Tokenizer Detail Buyers Miss
Anthropic shipped Opus 4.7 with a new tokenizer that uses 1.0× to 1.35× more tokens for the same text compared to Opus 4.6, depending on content type (Anthropic docs). On code-heavy workloads, that quietly adds 20-35% to the input bill at the same listed rate. The headline price did not change. The effective bill often did.
What This Means in Practice
The decision is workload-shaped, not price-page-shaped. High-volume agentic pipelines often land cheaper on GPT-5.5, since output volume drives the bill. Reasoning-heavy refactors across large codebases often justify Claude's pricing on cost-per-merged-PR rather than cost-per-token. This is the same hidden-cost pattern that shows up across AI automation for businesses more broadly: sticker prices rarely reflect what you actually pay.
📌 Pro Insight: Before committing to either platform for high-volume work, run 100 representative prompts through both models' /count_tokens endpoint and multiply by published rates. The "cheaper" model on the rate card is rarely the cheaper model on your actual workload.
Pick the Right Tool for Your Workflow
The right pick depends on the specific job. Here are seven common workflows in 2026 and the tool that fits each best, mapped to the strengths covered above.
- Solo content creator publishing long-form weekly → Claude Opus 4.7. Stronger long-form prose, fewer AI-style cliches, and better tone consistency across thousands of words.
- Developer doing multi-file refactors in a large repo → Claude (via Claude Code). Top scores on SWE-Bench Pro and CursorBench, plus deeper codebase reasoning across many files.
- Developer building autonomous coding agents → GPT-5.5 (via Codex). Wins Terminal-Bench 2.0 by 13+ points and uses far fewer output tokens per task.
- Marketer producing image-paired social content → ChatGPT. Native image, voice, and video output sit inside the same chat. Claude does not generate images.
- Researcher synthesizing recent web sources → ChatGPT (Deep Research). More mature browsing and multi-source synthesis, with a 5-point edge on BrowseComp.
- Researcher analyzing uploaded PDFs, books, or corpora → Claude. Better precision recall on long documents and full 1M-token context for big file collections.
- Student juggling notes, summaries, and study sessions → Claude. Long context handles full lecture sets and textbooks without breaking. For a wider toolkit beyond just Claude and ChatGPT, see our guide to the best AI study tools for students.
Common Mistakes When Choosing Between Claude & ChatGPT
Most bad choices come from the same five mistakes. Avoid these and the cost-vs-quality tradeoff gets cleaner.
- Choosing on benchmark scores alone. Lab numbers don't always match your workload. Expert tip: Run 50 of your real prompts through both before picking.
- Assuming 1M context equals 1M usable retrieval. Long-context recall drops on real-world tasks; the max is rarely the practical ceiling. Expert tip: Test recall on your specific document type before committing.
- Comparing per-token price without measuring per-task cost. Sticker rates ignore the output-token gap and tokenizer overhead. Expert tip: Calculate cost per finished task on a sample workload.
- Locking into one platform when usage limits cause friction. Pro tier caps hit hard at heavy use on either side. Expert tip: Pay both $20 plans for a month and route work where it fits.
- Ignoring API rollout timing for procurement. Opus 4.7 hit Bedrock, Vertex, and Foundry day-one; GPT-5.5 staggered cloud availability after launch. Expert tip: Verify your cloud's launch-day SLA before signing multi-year.
FAQ — Claude vs ChatGPT 2026 Questions Answered
Is Claude better than ChatGPT in 2026?
Neither dominates in 2026. Claude Opus 4.7 leads on long-form writing, codebase work, and document analysis. GPT-5.5 leads on agentic coding, deep web research, and multimodal output including images and voice. The right pick depends on your specific workflow, not a single overall ranking.
Which is better for coding — Claude Opus 4.7 or GPT-5.5?
It depends on the type of coding. Claude Opus 4.7 wins codebase resolution and PR work, leading SWE-Bench Pro at 64.3% versus 58.6%. GPT-5.5 wins terminal-heavy and agentic pipelines, leading Terminal-Bench 2.0 at 82.7% versus 69.4%. Pick by task type, not by overall winner.
Is Claude Pro worth it compared to ChatGPT Plus?
Both cost $20/month, so the answer comes down to use case. Claude Pro suits writers, coders, and document-heavy researchers. ChatGPT Plus wins for marketers needing image generation and researchers using Deep Research. Many heavy AI users pay for both to avoid hitting usage caps on either.
Does Claude have image generation like ChatGPT?
No. Claude does not generate images, audio, or video. ChatGPT runs native multimodal output across all three formats inside the same chat. If you need image-paired writing or voice output, ChatGPT is the only choice between the two. Claude focuses on text and reasoning.
Can I use Claude and ChatGPT together?
Yes, and many serious users do. A common 2026 setup pays both $20 consumer plans (~$40/month total) and routes work by strength: Claude for long-form writing and coding, ChatGPT for visual content and web research. The combined cost stays modest compared to enterprise tier alternatives.
Which has the better context window — Claude or GPT-5.5?
They tie on size. Both Claude Opus 4.7 and GPT-5.5 ship with 1M-token context windows and 128K max output tokens. The difference shows up in long-context recall reliability and how each model uses tokens, not in the headline window size itself. Test on your workload.
Conclusion: Pick by Workload, Not by Brand
Neither Claude Opus 4.7 nor GPT-5.5 wins overall in 2026. The right pick is workload-shaped. For long-form writing and codebase resolution, Claude is the stronger default. For agentic coding, terminal-heavy automation, and multimodal output, GPT-5.5 wins. For research, the choice splits cleanly: ChatGPT for live web sources, Claude for uploaded documents.
The cleanest way to decide is to use both for one week on real work. Track cost per finished task, not cost per token. The model that finishes a job in fewer tokens often beats the one with the cheaper rate card. For a wider toolkit beyond just these two, see our roundup of the best AI study tools for students.
Related Articles




